Interview | Note-2 数据库
Q:如何设计一个关系型数据库?
- RDBMS
- 存储模块
- 程序实例(用逻辑结构映射物理结构)
- 存储管理
- 数据的格式和分隔进行统一的管理,即把数据通过逻辑的形式给组织和表示出来
- 多行数据组成块、页,减少逐行读取浪费的效率
- 缓存机制
- 直接从内存中取出已使用过的高频数据,减少I/O
- 优化访问速率(数据多行组成块或页)
- SQL解析
- 将SQL编译解析成机器可识别的语言
- 缓存到内存中,提升SQL执行的效率(已编译好)
- 日志管理
- 对操作做记录
- 权限划分
- 容灾机制
- 考虑异常情况的处理、恢复、恢复的程度
- 索引管理、锁管理
- 提高数据库查询的速度,支持并发
- 存储管理

索引模块
为什么要使用索引?
块/页:由多行数据组成
全表扫描
- 将全表的数据一次性全部或分批次的加载到数据当中
- 将块、页轮询查找
- 数据之间挑选关键信息,依据字典的设计思路,将相关数据分类,按照特定的关键信息进行索引查询,以提高查询速度
什么样的信息能成为索引?
- 能够将查询限定在一定查找范围内的字段(主键、唯一键、普通键)
索引的数据结构
- 生成索引、建立二叉查找树进行二分查找
- 建立B-Tree、红黑树、B+-Tree(MySQL)、Hash、BitMap
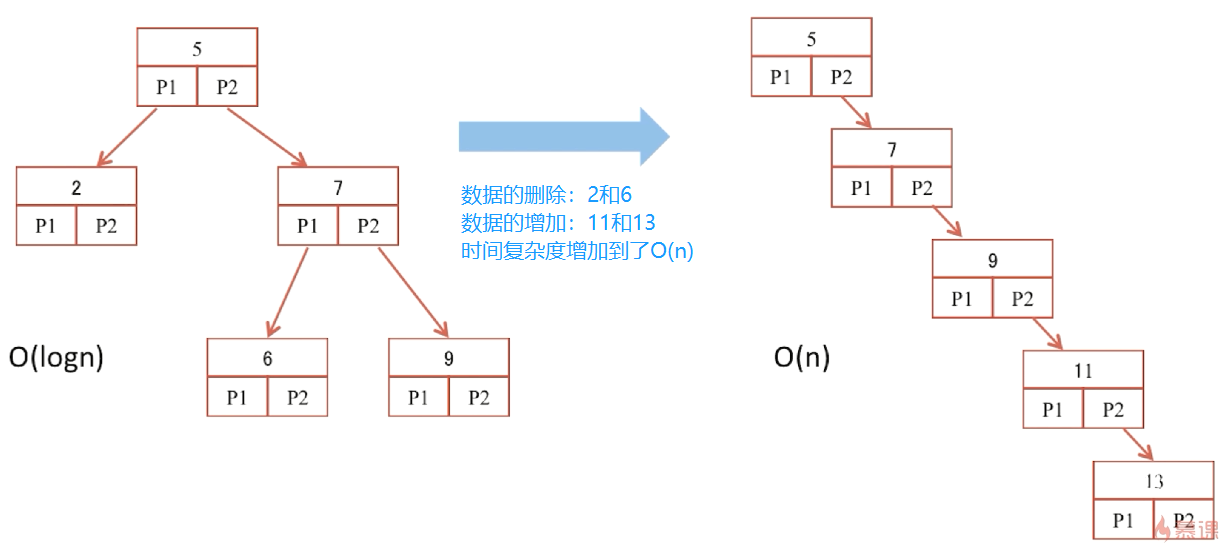
二叉查找树
- 每一次的数据操作,都与I/O有关,随着数据增多,树的高度也增加,随之I/O增加
B-Tree

- 定义
- 根节点至少包括两个孩子
- 树中每个节点最多含有m个孩子
- 除根节点和叶节点外,其他每个节点至少由ceil(m/2)个孩子
- 所有叶子节点都在同一层
- 假设每个非终端结点中包含有n个关键字(蓝色)信息,其中
- Ki为关键字,且关键字按顺序升序
- 关键字的个数n必须满足,[ceil(m/2)-1] <= n <= m-1
- 非叶子结点的指针,左指针子树的关键字都小于该左关键字,右指针子树的关键字都大于该右关键字,其余在该范围子树内
- 目的
- 使得每个索引块存储更多的信息、树的高度尽可能矮,减少I/O次数
- 拒绝变为线性情况
- 时间效率
- O(logn)
B+-Tree
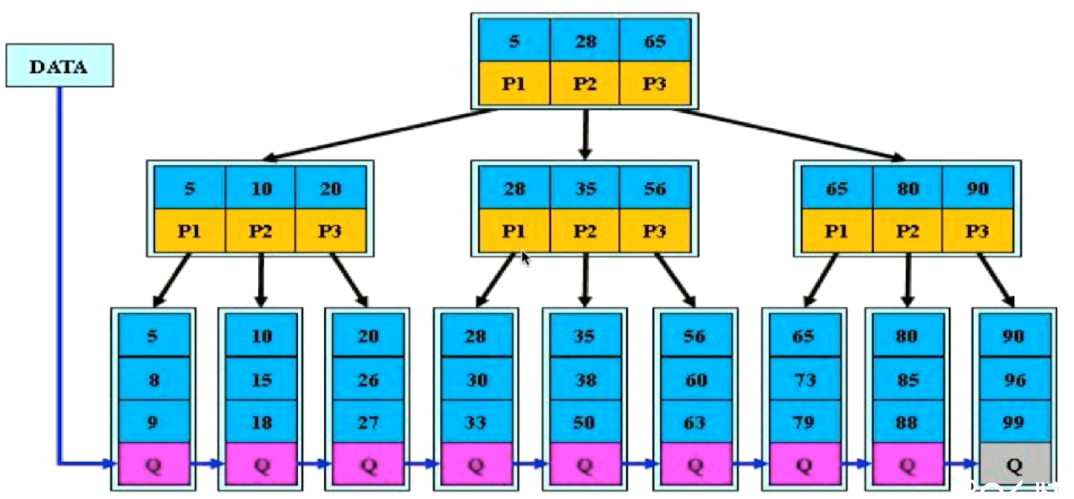
- B+树是B树的变体,定义基本与B树相同,还包括
- 非叶子节点的子树与关键字个数相同
- 可以存储较B树更多的关键字
- 非叶子界面的子树指针P[i],指向关键字值[K[i] , K[i+1])的子树
- 例如10,最后一个关键字的大小18,一定小于20;或者18可以是该子树的关键字值
- 非叶子节点仅用于索引,数据都保存在叶子节点中
- 所有检索从根开始,到叶子结束
- 非叶子节点不存储数据,所有可以存储更多的关键字,更矮,更快
- 所有叶子节点均有一个链指针指向下一个叶子节点,按升序
- 例如5-8-9,10-15-18
- 方便做范围统计
- 非叶子节点的子树与关键字个数相同
- B+树,更适合用来做存储索引
- 磁盘读写代价更低(不存放数据,只存放索引)
- 查询效率更加稳定(必须从根到叶子,长度相同)
- 更利于对数据库的扫描(遍历叶子节点即可完成对全部关键字信息的扫描)
Hash & BitMap
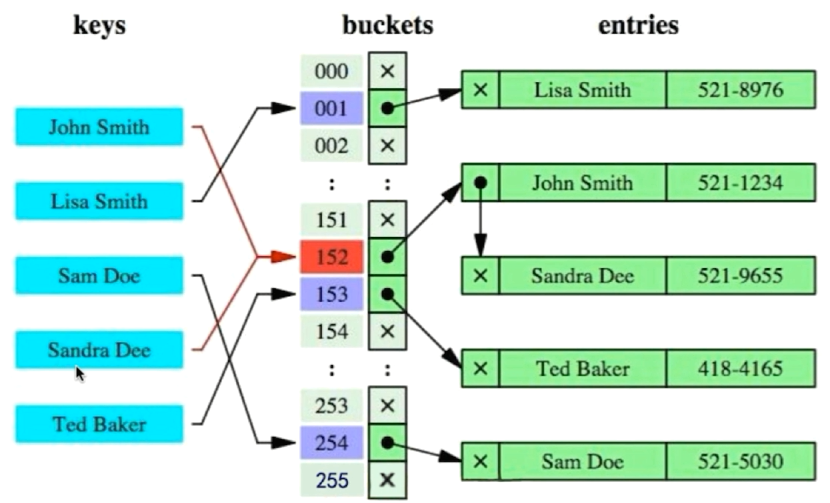
- Hash索引,根据Hash函数的计算,一次定位找到所需数据所在的bucket
- 例如,对Sandra Dee的keys进行一次Hash运算,便能找到所在的buckets
- 将152的entries全部加载到内存当中
- 由于该entries是一个链表,顺着指针找到Sandra Dee
- Hash索引的缺点在于
- 仅能等值查询,不能使用范围查询
- 无法被用来避免数据的排序操作
- 不能利用部分索引键查询(组合索引键计算的Hash值,而不是单独计算)
- 不能避免表扫描
- 遇到大量Hash值相等的情况下,性能不一定高于B树
- 大量记录指针信息存放在同一个buckets的情况,导致整体性能低下
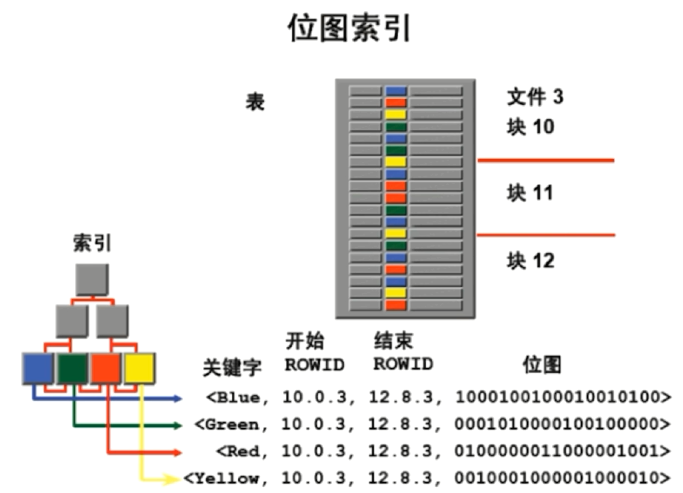
- BitMap位图索引
- 当表中的某个字段,只有几种值的时候(性别-男/女)
- 位图表示行是否存在该值
- 锁的粒度非常大(适合并发少、统计多的系统)
密集索引和稀疏索引
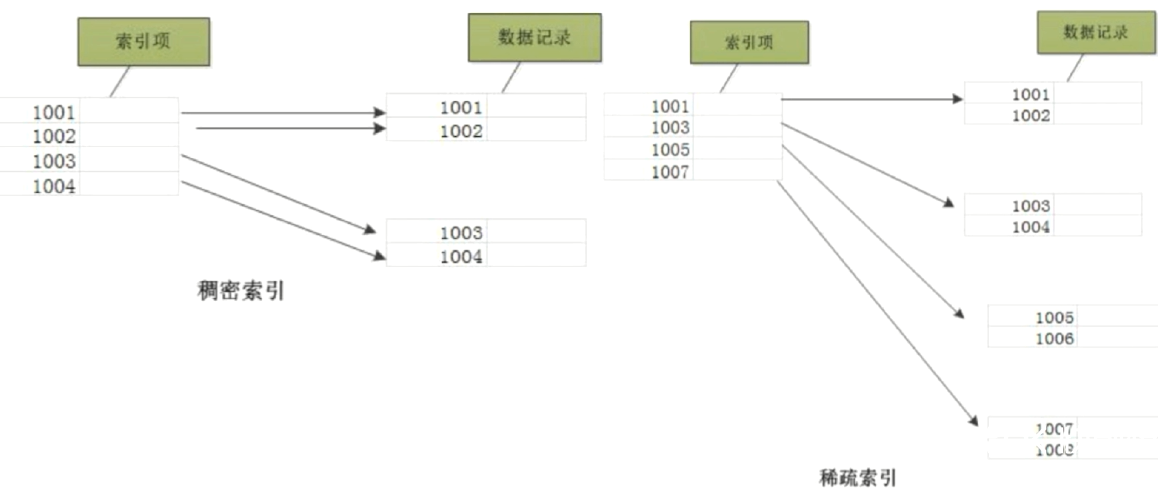
- 区别
- 密集索引文件中的每个搜索码值都对应一个索引值
- 叶子节点不仅保存键值,还保存位于同一行其它列的信息,用于密集索引决定了表的物理排列顺序;一个表只能有一个物理排列顺序(即只能有一个密集索引)
- 稀疏索引文件只为索引码的某些值建立索引项
- 叶子节点仅保存了键位信息(或主键信息),以及该行数据的地址
- 密集索引文件中的每个搜索码值都对应一个索引值
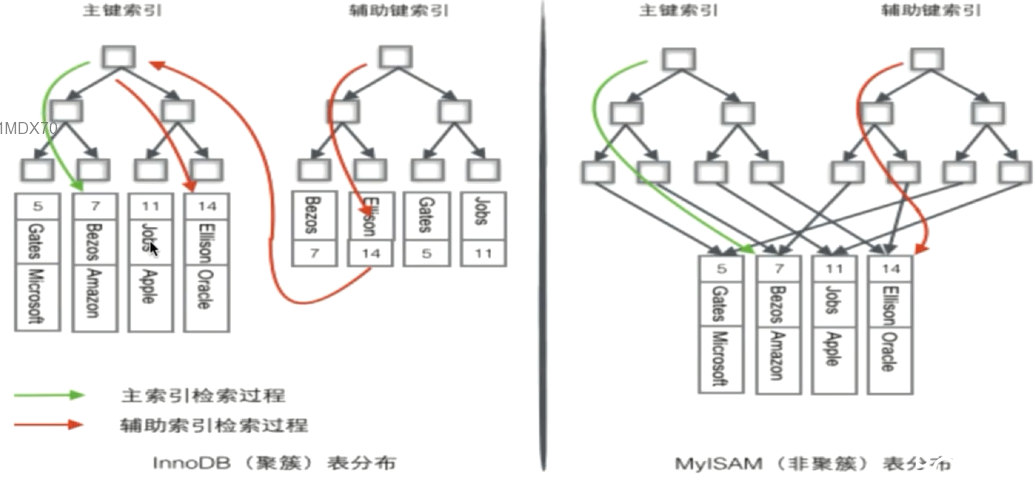
- 举例MySQL的存储引擎
- MyIsam
- 其索引均属于稀疏索引
- InnoDB
- 有且仅有一个密集索引(选取规则如下)
- 若一个主键被定义,该主键则作为密集索引
- 若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
- 若不满足以上条件,innodb内部会生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和其对应的主键值,包含两次查找(一次是次级索引自身,再查找主键)
- 有且仅有一个密集索引(选取规则如下)
- MyIsam
- 表的结构信息存储在.frm文件内
- Innodb的.ibd文件,存储数据和索引
- MyIsam的.MYI存储索引、.MYD存储数据
调优SQL
定位并优化慢查询SQL
思路
- 根据慢日志定位慢查询SQL
1 | show variablies like '%query%'; |
1 | # 例200W条数据 |
- 使用explain等工具分析SQL
1 | explain select name from person order by name desc; |
- 修改SQL或尽量让SQL使用索引
1 | # 查询其他更具有唯一性的字段 |
1 | explain select count(id) from person; |
联合索引的最左匹配原则的成因
联合索引:由多列组成的索引
最左匹配原则:对A、B两列设置联合索引,使用语句where a = b 或 where a时,会使用该联合索引进行查询;但是使用where b的时候则不会使用该联合索引进行查询
1 | KEY 'index_area_title'('area','title'); |
- 最左匹配原则
- MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
- 例如a = 3 and b = 4 and c > 5 and d = 6
- 如果建立(a,b,c,d)顺序的索引,d是用不到索引的
- 如果建立(a,b,d,c)顺序的索引,则全部都可以用到索引,a,b,d的顺序可以任意调整
- =和in可以乱序
- 比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器可以优化索引可以识别的形式
成因
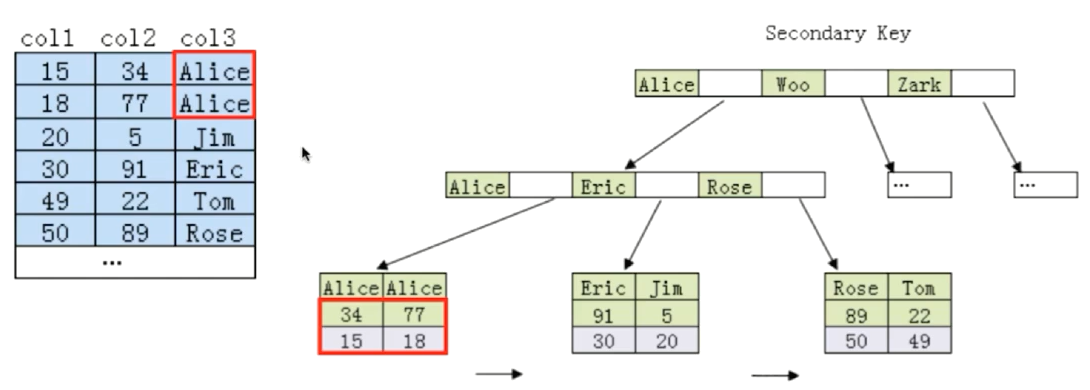
- MySQL建立联合索引的规则是首先会对联合索引的最左侧(即索引的第一个字段进行排序)
- 在第一个字段排序的基础上,再对索引上第二个字段进行排序(类似order by col1,col2)
- 那么第一个字段是绝对有序的,而第二个字段则是无序的
- 因此在一般情况下,直接只用第二个字段判断是使用不到索引的
索引是越多越好吗
- 数据量小的表不需要建立索引,建立会增加额外的索引开销
- 数据变更需要维护索引,更多的索引意味更多的维护成本
- 更多的索引意味更多的存储空间
锁模块
MyISAM与InnoDB关于锁的区别
- MyISAM默认表级锁,不支持行级锁
- InnoDB默认用行级锁,也支持表级锁
- 读锁(共享锁)、写锁(排它锁)
MyISAM
- MyISAM在进行查询的时候,会自动给表加上一个读锁,而对数据进行增删改的时候,会加上表级的写锁
- 当读锁没有被释放的时候,另外一个session想要对同一个表加上写锁,就会被阻塞,直到所有的读锁被释放为止
1 | # 显式添加读锁 |
InnoDB
- 支持事务,可以通过session获取锁,暂时不自动提交的方式,模拟并发访问的过程
- 不走索引的操作,会执行表级锁
- MySQL默认自动提交事务
1 | # 两个session对同一行数据进行修改 |
- 结果发现,并没有出现第二个session在执行时出现阻塞的情况
- InnoDB使用的是二段锁,即加锁和解锁两个步骤,即先对同一个事务里的一批操作分别进行加锁,然后commit的时候,再对事务里的加锁统一进行解锁,而当前的commit是自动操作
1 | # 关闭session的自动提交 |
- 因为InnoDB对select进行了改进,第一个session中的select操作并没有对该行上锁,所以导致更新成功
- 检验InnoDB支持行级锁
1 | # session1对id=3的数据加共享锁 |
适用场景
- MyISAM
- 频繁执行全表count语句
- 对数据进行增删改的频率不高,查询非常频繁
- 没有事务
- InnoDB
- 数据CRUD频繁
- 可靠性要求比较高,要求支持事务
数据库锁的分类
- 按锁的粒度:表级锁、行级锁、页级锁
- 按锁的级别:共享锁、排它锁
- 按加锁的方式:自动锁、显式锁
- 按操作划分:DML锁、DDL锁
- 按使用方式:乐观锁、悲观锁(https://www.imooc.com/article/details/id/44217)
数据库事务的四大特性ACID
- 原子性:要么全做,要么全不做
- 一致性:数据库应保证从一个一致性状态到另一个一致性状态(数据间的完整性约束)
- 隔离性:多个事务并发执行时,一个事务的执行,不能影响另一个事务的执行
- 持久性:一个事务一旦提交,对数据库数据的修改应该是永久影响
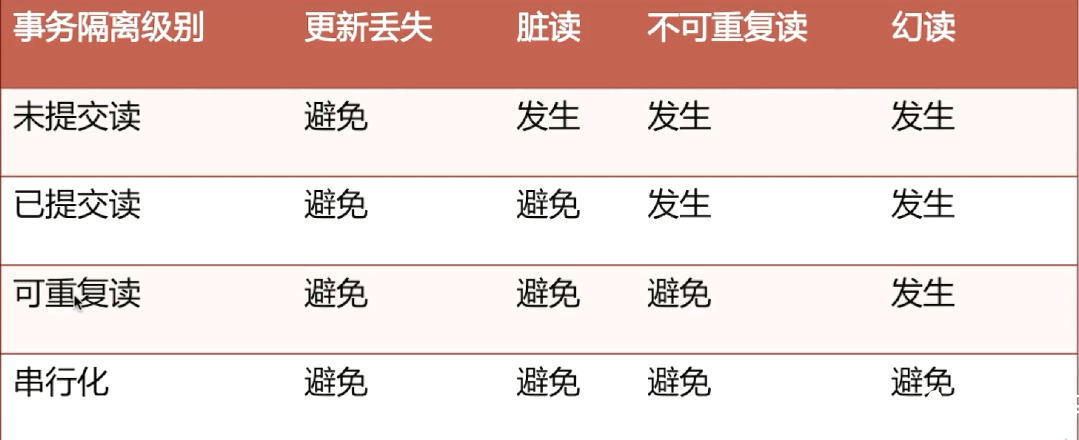
事务隔离级别以及各级别下的并发访问问题
ORACLE(READ-COMMITED)/ MYSQL(REPETABLE-READ)
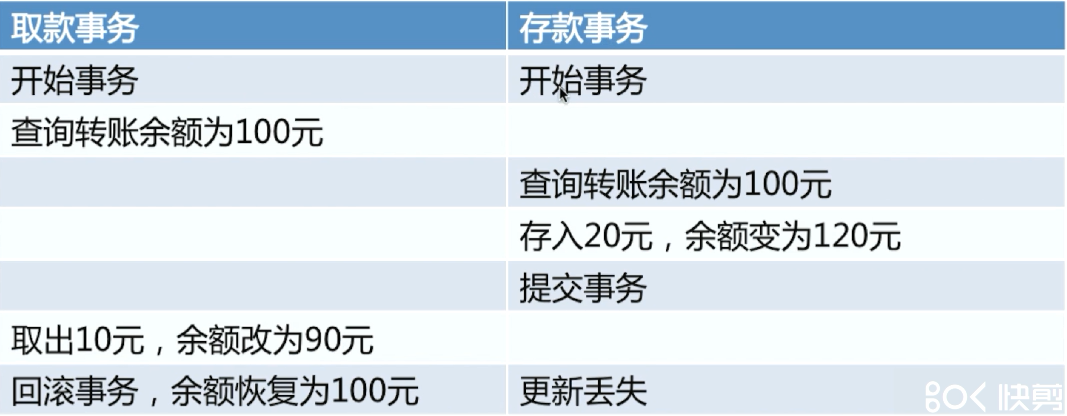
更新丢失
MySQL所有事务隔离级别在数据库层面上均可避免
定义:事务的更新,覆盖了另一个事务的更新
脏读
READ-COMMITED事务隔离级别以上可避免
定义:一个事务读取到另一个未提交事务的数据(即:读到了别的事务回滚前的脏数据)
- 导致:网络原因修改失败失败情况下,回滚会失败,数据修改错误
不可重复读
REPETABLE-READ事务隔离级别以上可避免
定义:事务A首先读取一条数据,然后执行事务逻辑时,事务B将该数据改变,然后事务A再次读取,发现数据不匹配
- 导致:多次数据不同的情况下,进行某次获取数据的结果进行修改,则会造成数据紊乱的问题
幻读
- SERIALIZABLE事务隔离级别可避免
- 定义:事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据(即:当前事务读第一次取到的数据比后来读取到数据条目少)
InnoDB可重复读隔离级别下如何避免幻读
当前读和快照读
- 当前读
- 读取当前记录,而且读取之后还需要保证其他并发事务不能修改当前记录,对读取的记录加锁
- select … lock in share mode;
- select … for update;
- update,delete,insert
- 快照读
- 不加锁的非阻塞读,select
- 有可能读取的数据不是最新版本
RC级别下的InnoDB的非阻塞读如何实现
- 数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
- DB_TRX_ID:表示最后一个事务的更新和插入
- DB_ROLL_PTR:指向当前记录项undo log信息
- DB_ROW_ID:标识插入的新数据行的ID
- undo日志
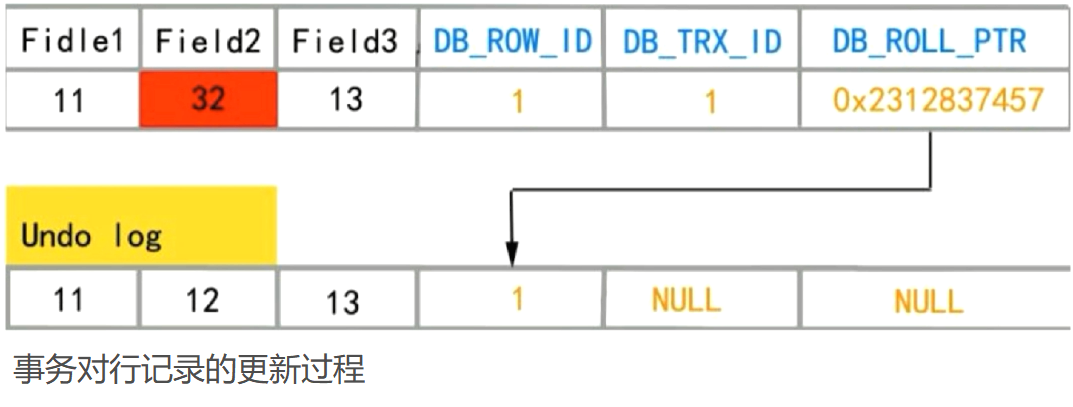
- insert-undo-log
- 事务对新记录的undo-log,只在事务回滚时需要,在事务提交后可以立即丢弃
- update-undo-log
- 事务进行delete或者update操作,不仅在事务回滚时需要,快照读也需要,不可随意删除;只有数据库的快照读不涉及该undo-log时,才可删除
- read view
RR级别下的InnoDB的非阻塞读如何实现——使用next-key锁
- 表象:快照读(非阻塞读)——伪MVCC(行级锁的变种)
- 内在:next-key锁(行锁 + Gap锁)
- 行锁:对单个行记录上锁
- Gap锁:索引树中,插入记录的空隙,锁定一定范围,但不包括记录本身;防止同一事务的两次当前读,出现幻读的情况
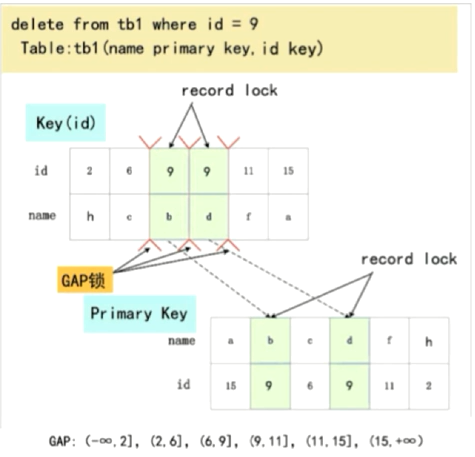
对主键索引或唯一索引会用到Gap锁吗
- 如果where条件全部命中,则不用Gap锁,只会加记录锁
- 如果where条件部分命中或者全都不命中,则会加Gap锁
- 部分命中情况下,Gap锁的范围,则是条件的最小和最大情况的范围
Gap锁会用在非唯一索引或者不走索引的当前读中
- 非唯一索引(左开右闭区间)
- 不走索引
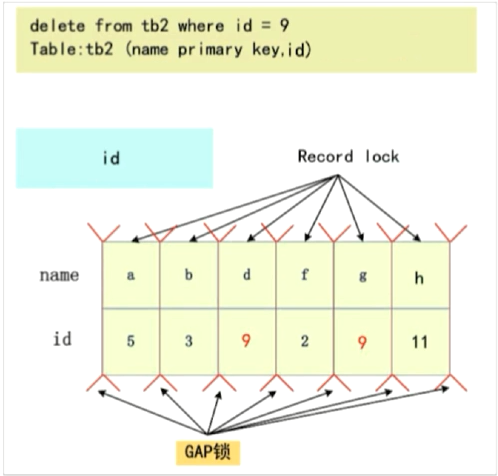
- 当前读不走索引的时候,都所有的Gap都上锁(类似锁表),防止幻读的效果
关键语法
GROUP BY
- 满足SELECT子句中的列名必须为分组列或列函数(要么是GROUP BY需要用到的列;要么是统计关键字的列)
- 列函数对于GROUP BY子句定义的每个组各返回一个结果
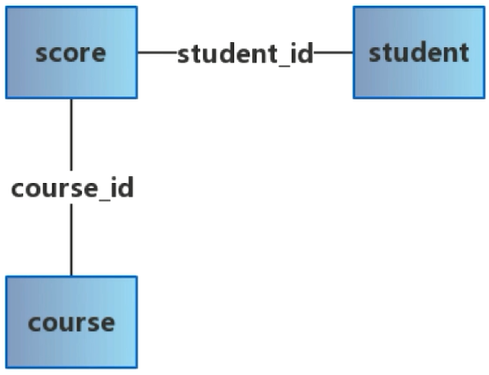
1 | # 查询所有同学的学号、选课数、总成绩 |
HAVING
- 通常与GROUP BY子句一起使用(指对GROUP BY的内容再筛选)
- WHERE过滤行,HAVING过滤组
- 出现在同一SQL的顺序:WHERE > GROUP BY > HAVING
1 | # 查询平均成绩大于60分的学号和平均成绩 |